El procesamiento del lenguaje natural y el SEO son tendencia en nuestro sector.
El año pasado Google abrió la puerta a la búsqueda semántica y basada en entidades, lo que supone un cambio de paradigma en la manera de posicionar contenidos en este buscador. Entender este cambio es fundamental para los marketers. Por eso, en este artículo vamos a ver qué es el procesamiento del lenguaje natural y cómo lo está utilizando Google en sus búsquedas.


¿Qué es el procesamiento del lenguaje natural y cómo se aplica en las búsquedas?
El procesamiento del lenguaje natural (PLN) hace posible entender el significado de palabras, oraciones y textos para generar información o textos nuevos. Incluye la comprensión del lenguaje natural (CLN) y la generación de lenguaje natural (GLN).
El procesamiento del lenguaje natural tiene múltiples aplicaciones, como:
- Reconocimiento de voz (texto a voz y voz a texto).
- Segmentar voz en palabras individuales, oraciones y frases.
- Reconocer las formas básicas de las palabras y obtener información gramatical.
- Reconocer las funciones de palabras individuales dentro de una frase (sujeto, verbo, objeto, artículo, etc.).
- Extraer el significado de oraciones y partes de oraciones, como “demasiado largo”, “hacia la carretera” o “la carrera larga”.
- Reconocer el contexto en el que aparecen las oraciones, las relaciones entre ellas y las entidades presentes.
- Realizar análisis lingüísticos y de opinión de los textos.
- Traducciones (incluyendo traducciones para asistentes de voz).
- Chatbots y otros sistemas de preguntas y respuestas.
Entre los componentes clave del procesamiento del lenguaje natural destacan los siguientes:
- Tokenización: divide una oración en diferentes elementos.
- Etiquetado del tipo de palabra: objeto, sujeto, predicado, adjetivo, etc.
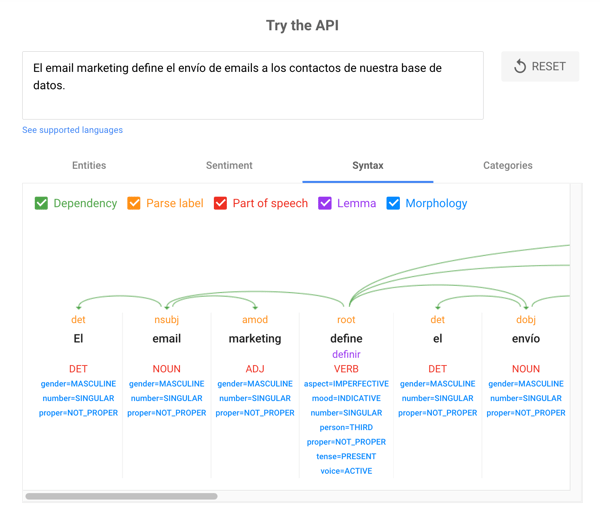
- Dependencias entre palabras: identifica las relaciones entre palabras en función de reglas gramaticales.
- Lematización: determina si una palabra tiene diferentes formas y normaliza las variaciones. Por ejemplo, la forma base de “coches” es “coche”.
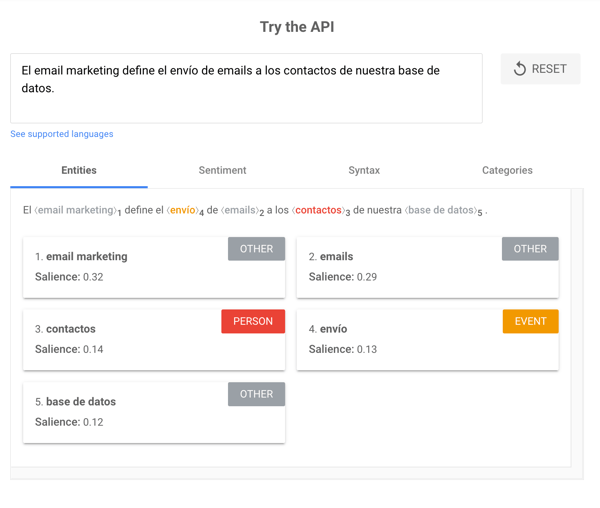
- Análisis y extracción de entidades: identifica las palabras con un significado conocido y las asigna a entidades. Normalmente las entidades incluyen organizaciones, personas, productos, lugares y cosas (nombres). En una oración, los sujetos y los objetos son identificados como entidades.
- Puntuación de salience: determina cuánto de conectado está un texto con un tema determinado. Normalmente, la salience se determina a través de las palabras comúnmente mencionadas y las relaciones entre entidades en bases de datos como Wikipedia.
- Análisis de opiniones y actitudes expresadas en un texto.
- Categorización de textos: identifica de qué trata el texto en general.
- Clasificación de textos según funciones: identifica la función o el propósito del texto.
- Extracción del tipo de contenido: los motores de búsqueda pueden determinar el tipo de contenido de un texto sin datos estructurados, a partir de elementos como el HTML, el formateado y el tipo de datos.
- Identificación de significados implícitos a partir del formato: por ejemplo, podemos deducir la importancia del texto según el tamaño de fuente, la presencia de listas, etc.
Durante años, Google ha entrenado a sus modelos de lenguaje, como BERT o MUM, para interpretar texto, consultas de búsqueda e incluso contenidos de vídeo y audio. Estos modelos se alimentan mediante procesamiento del lenguaje natural.
Estas son las principales áreas en las que Google utiliza el procesamiento del lenguaje natural:
- Interpretar consultas de búsqueda.
- Clasificar documentos según su asunto y su objetivo.
- Analizar entidades en documentos, consultas de búsqueda y publicaciones de redes sociales.
- Generar featured snippets y respuestas a búsquedas de voz.
- Interpretar contenidos de vídeo y audio.
- Ampliar y mejorar el gráfico de conocimiento.
Búsquedas de Google con PLN: BERT y MUM
BERT es la novedad más importante en las búsquedas de Google desde RankBrain. Esta actualización basada en PLN se diseñó para mejorar la interpretación de las consultas de búsqueda y afectó al 10% de las consultas de búsqueda en el momento de su lanzamiento.
BERT no solo es importante para interpretar las consultas, sino también para clasificar y generar featured snippets, así como para interpretar cuestionarios de texto en documentos.
En 2021 se anunció el lanzamiento de MUM, que también está basado en el PLN. Este modelo es multilingüe, puede responder a consultas de búsqueda complejas con datos multimodales y procesa información en diferentes formatos multimedia. De hecho, además de texto, MUM también entiende imágenes, vídeos y archivos de audio.
MUM combina diferentes tecnologías para hacer que las búsquedas de Google sean aún más semánticas y basadas en contexto para mejorar la experiencia de usuario.
Tanto BERT como MUM usan el PLN para avanzar en la búsqueda semántica y responder mejor a las necesidades de los usuarios. Esto permite pasar de una búsqueda basada en cadenas de texto a una basada en “cosas” o entidades. El objetivo de Google es desarrollar una comprensión semántica de las consultas de búsqueda y los contenidos.
Al identificar las entidades de las consultas de búsqueda, el significado y las intenciones reales del usuario quedan mucho más claros. El motor de búsqueda ya no tiene en cuenta las palabras individuales, sino que las ubica en el contexto de toda la consulta.
Estos pasos se aplican a las búsquedas de Google con PLN:
- Identificar la temática en la que se ubica la búsqueda. Si el contexto temático está claro, Google puede seleccionar un corpus de documentos de texto, vídeos e imágenes potencialmente apropiados como resultado. Esto es particularmente difícil si el término de búsqueda es ambiguo.
- Identificar entidades y su significado en la búsqueda de términos (reconocimiento de entidades).
- Entender el significado semántico de una consulta de búsqueda.
- Identificar la intención de la búsqueda.
- Anotación semántica de la consulta de búsqueda.
- Ajustar el término de búsqueda.
El papel del minado de entidades en la búsqueda de Google
El gráfico del conocimiento es el índice de entidades de Google. En él, todos los atributos, documentos e imágenes digitales se organizan alrededor de la entidad.
En la actualidad, el gráfico de conocimiento y el índice “clásico” de Google se están utilizando en paralelo. Si Google identifica que una consulta de búsqueda contiene una entidad almacenada en el gráfico de conocimiento, Google accede a la información de ambos índices, centrándose en la información referente a la entidad.
Para poder intercambiar información entre el índice clásico y el gráfico de conocimiento, es necesario contar con una interfaz o API que sea capaz de averiguar esta información:
- Si un contenido contiene entidades.
- Si hay una entidad principal dentro del contenido.
- A qué temáticas puede asignarse la entidad principal.
- Quién es el autor o la entidad responsable del contenido.
- Cómo se relacionan entre sí las entidades presentes en el contenido.
- Qué propiedades o atributos se pueden asignar a las entidades.
El procesamiento del lenguaje natural es fundamental para que Google sea capaz de identificar las entidades presentes en un texto y lo que significan, lo que posibilita extraer conocimientos a partir de datos no estructurados. A su vez, esto permite identificar las relaciones entre entidades y seguir desarrollando el gráfico de conocimiento.
Dentro de una oración, los sustantivos son entidades potenciales y los verbos suelen representar la relación de las entidades entre sí. Los adjetivos describen la entidad y los adverbios describen la relación.
Hasta ahora, Google ha hecho muy poco uso de información no estructurada, como páginas web, para desarrollar el gráfico del conocimiento. Aunque sus capacidades de PLN son bastante buenas, no se consiguen resultados satisfactorios al evaluar información extraída automáticamente. En particular, es difícil garantizar que toda la información es correcta y precisa.
La conclusión de todo ello es que las entidades almacenadas hasta ahora en el gráfico de conocimiento son tan solo la punta del iceberg. En la actualidad estamos empezando a ver el impacto de la búsqueda basada en entidades en las SERP, ya que Google tarda cierto tiempo en comprender el significado de las entidades individuales.
Dentro de este proceso, las entidades que se incorporan primero son las que tienen más relevancia social. Las más relevantes están incluidas en Wikidata y Wikipedia.
La mayor tarea a la que se enfrentan las búsquedas de Google con PLN es identificar y verificar las entidades “long-tail” e incorporarlas progresivamente a la búsqueda semántica.
Conclusión: las búsquedas de Google con PLN están aquí para quedarse
Como hemos visto en este artículo, BERT y MUM utilizan el procesamiento del lenguaje natural para interpretar consultas de búsqueda y contenidos. Además, gracias a ellos, las bases de datos de conocimiento como el gráfico de conocimiento de Google pueden crecer a escala y hacer que la búsqueda semántica siga avanzando.
Está claro que Google está apostando fuerte por las búsquedas con PLN y que esta es una tendencia que se mantendrá en el futuro. A medida que las búsquedas basadas en entidades sigan desarrollándose, cada vez veremos más cómo los resultados de búsqueda de este tipo reemplazan a las búsquedas tradicionales basadas en palabras y frases clave.

Laia Cardona
Responsible for content and brand visibility strategy at Cyberclick, with an Allbound approach and specialization in SEO, GEO (Generative Engine Optimization), and AI-powered automation. Advanced HubSpot CRM management: database segmentation, workflows, lead nurturing, scoring, and reporting. Background in digital marketing, corporate communications, and journalism—combining strategy, creativity, and technology to attract and convert qualified leads.



Deja tu comentario y únete a la conversación