El inminente fin de las cookies supone que tenemos que replantear cómo hacemos marketing digital. Ya no podemos utilizar esta tecnología para hacer un seguimiento de los usuarios y de sus hábitos de consumo, pero por suerte existen otras soluciones que nos permiten hacer segmentación de mercado al tiempo que respetamos la privacidad de cada usuario. Una de estas soluciones son los algoritmos de clustering.


¿Qué son los algoritmos de clustering?
Un algoritmo de clustering es una solución para agrupar los elementos de un conjunto de datos según su similaridad, de forma que se generan diferentes grupos o clústeres que contienen objetos similares entre sí.
Los algoritmos de clustering se utilizan para resolver problemas de aprendizaje automático no supervisado, esto es, en los que los datos no tienen ninguna etiqueta. No podemos saber si hay patrones ocultos en los datos, así que dejamos que el algoritmo encuentre todas las conexiones que pueda.
Los algoritmos de clustering tienen múltiples usos, como encontrar los patrones climáticos de una región, agrupar artículos o noticias por temas o descubrir zonas con altas tasas de criminalidad.
En el mundo del marketing, son fundamentales para realizar segmentaciones de mercado, ya que permiten utilizar los datos que tenemos sobre los clientes para agruparlos en diferentes grupos en función de cómo son, cómo se comportan y cuáles son sus intereses. Todo esto nos permite hacer un marketing personalizado en función de las necesidades de diferentes usuarios sin necesidad de recurrir al uso de cookies.
Tipos de algoritmos de clustering
-
Basados en densidad. En este tipo de agrupamiento, los datos se organizan en función de áreas con altas concentraciones de datos rodeadas por áreas con bajas concentraciones de datos. El algoritmo localiza estos sectores con una alta densidad de datos y los denomina grupos. Estos grupos pueden adoptar cualquier forma y no se tienen en cuenta los valores atípicos.

-
Basados en centroides. Este tipo de algoritmo de clustering separa los puntos de datos en función de su distancia a los llamados “centroides”. Este centroide es la ubicación real o imaginaria que representa el centro de cada grupo. La agrupación basada en centroides es la más utilizada en machine learning y big data.
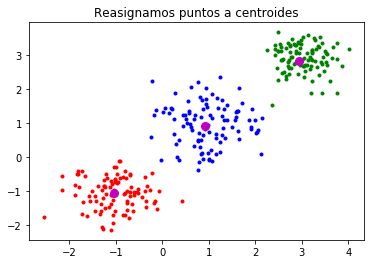
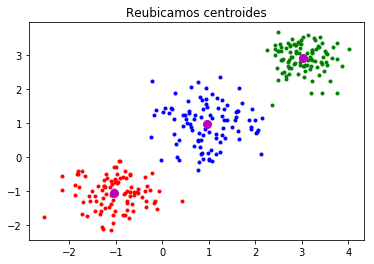
-
Basados en jerarquías. El agrupamiento basado en jerarquías consiste en crear un “árbol de grupos” que organiza los datos de arriba abajo. Es más restrictivo que otros tipos de algoritmos de clustering, pero muy útil para datos que ya están jerarquizados de por sí, por ejemplo, los que proceden de algún tipo de taxonomía.
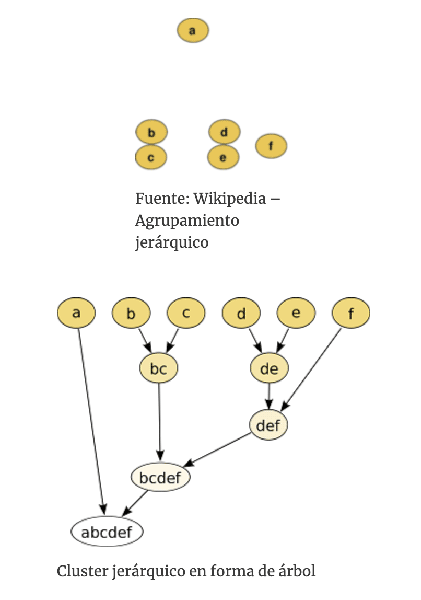
-
Basados en la distribución. El clustering basado en la distribución parte de identificar un punto central. A medida que un punto de datos se aleja de este centro, la probabilidad de que forme parte del mismo grupo disminuye. Se considera que todos los puntos de datos forman parte de un grupo en función de la probabilidad de que un punto pertenezca a un grupo determinado. Resulta muy útil cuando tenemos una idea a priori de cuál puede ser la distribución de los datos.


Pep Canals
Graduated with a degree in telecommunications and holds a PhD in photonics from the Institute of Photonic Sciences. He has more than 5 years of experience working with Google Ads and Google Analytics, managing SEM, and all campaigns type across the funnel from search to Youtube.



Deja tu comentario y únete a la conversación